
Machine learning: a quick review (part 5)
5- Not supervised learning
5-1- Unsupervised learning
unsupervised learning is a technique that determines patterns and associations in unlabeled data. This technique is often used to create groups and clusters [25]. Unsupervised learning is often used for exploratory analysis and anomaly detection because it helps to see how the data segments relate and what trends might be present. They can be used to preprocess your data before using a supervised learning algorithm or other artificial intelligence techniques.
Clustering is an unsupervised machine learning algorithm and it recognizes patterns without specific labels and clusters the data according to the features. A gif illustrating how K-means works. Each red dot is a centroid and each different color represents a different cluster. Every frame is an iteration where the centroid is relocated. (Source: gyfcat)
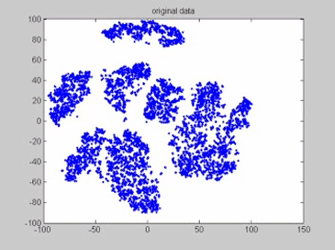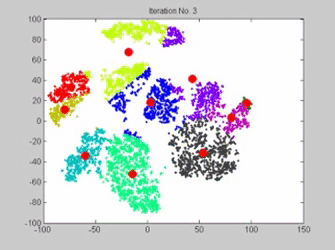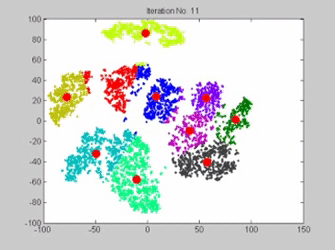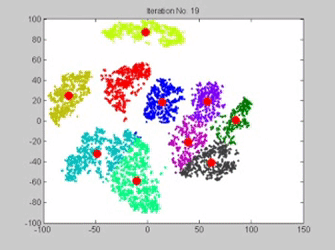
K-means clustering works by assigning a number of centroids based on the number of clusters given. Each data point is assigned to the cluster whose centroid is nearest to it. The algorithm aims to minimize the squared Euclidean distances between the observation and the centroid of cluster to which it belongs.
Principal component analysis (PCA)
Principal Component Analysis or PCA is a method of reducing the dimensions of the given dataset while still retaining most of its variance. Wikipedia defines it as, “PCA is defined as an orthogonal linear transformation that transforms the data to a new coordinate system such that the greatest variance by some scalar projection of the data comes to lie on the first coordinate (called the first principal component), the second greatest variance on the second coordinate, and so on.” PCA visualisation. The best PC (black moving line) is when the total length of those red lines are minimum. It will be used instead of the horizontal and vertical components (Source: giphy )

In the animation above, the datapoints are 2d, so there will be 2 principal components. The black line is the 1st principal component (PC1) and it’s proper position would be along the two magenta markers. Consider the projections of each point onto PC1 (the red dots). When PC1 is in the proper position, the red dots are the farthest away from each other. This is how we squeeze the most variance into the PC — by maximizing the distance between the red dots.
Then, PC2 is shown in gray. It is found in the same way, except it is constrained to be orthogonal to PC1. This constraint ensures that the components are not correlated with each other. Moreover, it should be noted that the animation also illustrates how the first PCs have the highest variance.
The problem with using PCA is that (1) measurements from all of the original variables are used in the projection to the lower dimensional space, (2) only linear relationships are considered, and (3) PCA or SVD-based methods, as well as univariate screening methods (t-test, correlation, etc.), do not take into account the potential multivariate nature of the data structure (e.g., higher order interaction between variables).

5-2- Reinforcement learning
Reinforcement learning is a technique that provides training feedback using a reward mechanism. The learning process occurs as a machine, or Agent, that interacts with an environment and tries a variety of methods to reach an outcome. The Agent is rewarded or punished when it reaches a desirable or undesirable State.



👌🏻👌🏻👌🏻🙏🏻best topic